

В рамках моего дипломного проекта мне предложили создать систему формирования проектных команд на основе технологий семантической паутины. Так как я уже переболел голым PHP, SQL, ZF, и имел опыт программирования на Ruby on Rails, ознакомившись с существующими гемами и решениями для работы с RDF, решил писать на нём, т.к. не очень люблю яву (да простят меня ява-разработчики), хотя она и является самым передовым языком в области semantic web, intelligent agents, data mining.
Первым шагом было изучение RDF, OWL, SPARQL, arc2, rdf.rb, Spira и прочих технологий, стандартов, модулей.
Сжатый экскурс в Semantic web
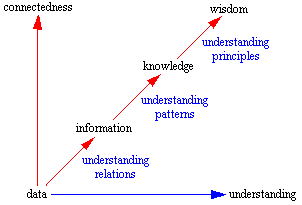 DIKW – Итак, у нас есть основные понятия – данные, информация, знания, мудрость, каждое из которых описывается с помощью предыдущего и добавляет то, чего нет на предыдущем уровне. Данные – базовый элемент, строительные блоки. Информация добавляет ответ на вопрос «что?», знание – «как?», мудрость – «почему?» (know-nothing, know-what, know-how, and know-why).
DIKW – Итак, у нас есть основные понятия – данные, информация, знания, мудрость, каждое из которых описывается с помощью предыдущего и добавляет то, чего нет на предыдущем уровне. Данные – базовый элемент, строительные блоки. Информация добавляет ответ на вопрос «что?», знание – «как?», мудрость – «почему?» (know-nothing, know-what, know-how, and know-why).Это сложно понять, поэтому переформулируем: Информация – это данные + метаданные(описание данных, данные о данных). Знание – это информация и правила вывода. То есть, когда мы имеем знание, правила вывода, мы можем из одной информации, получать новую информацию.
Если стандарт RDF оперирует преимущественно информацией, то OWL добавляет к RDF правила вывода новых фактов. И OWL описывается на RDF, всё верно.
Далее по стандартам – SPARQL – язык запросов к хранилищу, очень похож на SQL, но оперирует триплетами. Есть полно вариаций на тему SPARQL от различных производителей RDF storages, всё как в SQL.
nt3, turtle и прочие – вариации на тему RDF/XML. То есть, представляем триплетами в более удобном для чтения/записи/хранения/обработки виде.
В данных стандартах знания описываются триплетами – субъект, предикат, объект. Субъект – это то, что мы описываем, например яблоко. Предикат – это некоторое свойство субъекта, например «иметь цвет». Объект – это значение этого свойства для данного субъекта, например «зелёный». Таким образом мы можем описать знание в рамках RDF/OWL.
- Яблоко, это, класс
- Яблоко1, относится к классу, Яблоко
- Яблоко1, имеет цвет, Зелёный
- Червяк1, жрёт, Яблоко1
- Зелёный, в RGB, 00FF00 (литерал)
и т.д.
При этом всегда субъект и предикат являются сущностями, а объект может быть как сущностью, так и литералом (строкой, числом). Каждая сущность представляется URI. Например наше яблоко представляется в виде
http://example.com/apples_repo.xml.rdf#our_apple1
При этом помимо непосредственно данных (ABox) мы должны иметь метаданные (TBox), которые описывают классы, связи между классами, свойства классов, а так же, в случае OWL – взаимоотношения между классами. ABox обычно хранится в репозитории и является описанием конкретных сущностей этого мира, а TBox обычно хранится в так называемых онтологиях. Онтология обычно представляет из себя OWL или RDF файл (который, в свою очередь, может выгружаться некоторым хранилищем).
Таким образом в сумме мы получаем онтологическую базу знаний, которая описывает предметную область (классы, свойства, взаимоотношения) и конкретные сущности этой предметной области (людей, проекты, задачи, дома, товары).
А теперь главный вопрос – зачем всё это нужно, ведь мы можем всё то же самое хранить в реляционных/документных/графовых/объектных БД?
Эта сфера является развивающейся и на данный момент интересной, в первую очередь, с научной точки зрения. Однако уже сейчас существуют средства, которые умеют делать то, чего не умеют делать БД. Знания – это живые данные. Данные, из которых можно получить новые данные.
Если мы знаем, что Петя сын Маши, а Маша сестра Коли, а так же мы знаем, что сестра и брат – симметричные отношения, а брат матери является дядей, то мы можем сделать вывод, что Коля является дядей Пети.
На этом простом примере понятно, что онтологические БЗ в сочетании с системой логического вывода (reasoner) может находить новые факты. Так же существует направление интеллектуального анализа данных (data mining) – смежное с логическим выводом извлечение ранее неизвестных данных. И многие системы ИИ, экспертные системы работают именно с использованием онтологических БЗ, т.к. они отлично подходят для этого.
Также мы получаем распределенную семантическую паутину, знания из которой могут извлекать различные веб-сервисы и интерпретировать их в соответствии с онтологиями. Представьте кучу социальных сетей, в которых информация о каждом человеке может быть загружена в RDF-виде. Это дает возможность загружать и обрабатывать данные из всех этих сетей. Если раньше поисковики и агрегаторы извлекали совершенно лишенный семантики текст, то теперь они смогут извлекать и обрабатывать знания, заданные онтологией.
Итак, перейдем к практике.
С помощью Protege моделируем предметную область.
Готовые онтологии на OWL по ссылкам:
mera-max.ru/ontologies/competenceModel.rdf-xml.owl
mera-max.ru/ontologies/professionsModel.rdf-xml.owl
mera-max.ru/ontologies/staffModel.rdf-xml.owl
xmlns.com/foaf/spec
semanticweb.org/wiki/DOAP
www.semanticdesktop.org/ontologies/2008/05/20/tmo
Вкратце и упрощенно для нашего приложения – у нас есть люди (FOAF), у каждого человека есть аккаунт и набор компетенций, которыми он владеет, есть проекты (DOAP), в рамках проекта – задачи, каждая из которых требует набора компетенций, которые, в свою очередь, имеют уровень, который имеет численное представление.
Реализация
Используем Ruby 1.9.2
Используем Rails 3.0.7
Итак, мы все будем хранить в Sesame rdf storage кроме аккаунтов (т.к. было бы неприлично хранить хэши паролей в открытом SPARQL доступе)
Для хранения аккаунтов используем MongoDB
Для аутентификации используем Devise
Для работы с Sesame используем Spira, которая построена на rdf.rb
Для работы со SPARQL точкой доступа (которая в данном случае совпадает с Sesame storage) используем sparql-client
Для работы с MongoDB используем Mongoid
Для вёрстки используем haml
Пройдемся по исходникам на github.
- Были написаны monkey patches для корректной работы с Sesame и для более удобной работой со Spira как с маппером.
- Установлен и настроен Apache Tomcat и Sesame(openrdf-sesame+openrdf-workbench) на него
- Установлен и настроен MongoDB
- Написаны модели, вьюхи и контроллеры
- Установлены и настроены Devise, Mongoid стандартными средствами из консоли
- С помощью банального SPARQL запроса мы получили всех подходящих под требования кандидатов (более сложная модель приведена в документации к диплому):
def find_candidates
sel=Person._where
competences_with_level.each do |cwl|
cwl_id=:"cwl#{i}" #задаем идентификатор ксу
lev_id=:"lev#{i}"
val=:"val#{i}"
sel._where(:competences_with_level=>cwl_id) #человек должен иметь ксу
sel.where([cwl_id,CompetenceWithLevel.properties[:competence][:predicate],cwl.competence.subject]) #с данной компетенцией
sel.where([cwl_id,CompetenceWithLevel.properties[:level][:predicate],lev_id]) #с уровнем
sel.where([lev_id,CompetenceLevel.properties[:value][:predicate],val]) #который имеет значение
sel.filter("?val#{i} >= #{cwl.level.value}") #которое выше или равно тому, что требуется для данной задачи
end
sel.instances
end
Рассмотрим структуру модели Spira document, т.к. она отличается от ActiveRecord и Mongoid.
class Task
include Spira::Resource #миксин-стайл, как в монгоиде
type Vocabularies::Project.Task #определяет owl type
base_uri "http://example.org/tasks/" #адрес, по которому будут находиться наши сущности
default_vocabulary Vocabularies::Project #определяет словарь (онтологию), если предикат указан в виде символа или строки
property :name, :predicate=>Vocabularies::Project.hasName, :type=>String #свойство, значение – строчный литерал
property :project, :predicate=>Vocabularies::Project.belongsToProject, :type=>:Project #родительский объект. Удобная обёртка над триплетами.
has_many :competences_with_level, :predicate=>Vocabularies::Project.requires, :type=>:CompetenceWithLevel #И даже отношения многие-ко-многим. Аналогично есть возможность получать все субъекты в виде объектов ruby одним вызовом метода.
end
И давайте отметим наличие возможности извлекать данные из системы посредством не только SPARQL, но и отображение каждой сущности в nt виде:
def show
@competence = Competence.find(params[:id])
respond_to do |format|
format.html # show.html.erb
format.nt { render :inline => @competence.to_nt } #вот здесь
end
end
Итак, мы получили систему поиска кандидатов для выполнения проектов на основе требуемых и имеющихся компетенций.
Данное приложение далеко не идеально, не очень чистый код, нет модульных и интеграционных тестов, нет авторизации, это лишь интересный эксперимент, который стал для меня шагом в понимании и использовании семантических технологий и в области project management, project team formation. И надеюсь что он поможет заинтересовавшимся создавать в будущем семантические приложения на Ruby on Rails и развивать пока что не такие популярные семантические технологии.
Все дипломные документы (пояснительная записка, презентации, доклады на русском и английском языках) можете найти здесь (мало ли кому пригодится более подробное формальное описание, кстати в них много того, чего в приложении нет).
Я буду рад, если кому-то этот материал пригодится для создания ПО для ваших учебных проектов, однако, все-таки имейте и свою голову на плечах ;).
p.s. Спасибо моим дипломным руководителям доценту Д.В. Попову и А.Ф. Галямову, кафедра ВМК, ФИРТ, УГАТУ.
