
Привет Хабр! Меня зовут Саша Торопов, я ведущий архитектор системы высокочастотной алгоритмической торговли Tbricks от компании Itiviti.
Поскольку вы вряд ли о нас слышали, подробнее о том, кто мы и какое отношение имеем к биржам можно узнать тут.
Подробнее про Itiviti
Наша история началась в 1987 году.
Конец 80-х, Стокгольм, несколько амбициозных шведов решают открыть трейдинговую фирму. Их бизнес-план заключался в том, чтобы разработать для себя такой софт, который помогал бы им эффективнее других торговать на стокгольмской бирже. И всё случилось как нельзя лучше, идея опередила своё время. Стало понятно, что аналогов такого софта нет нигде в мире, а работает он прекрасно. Поэтому, имея на руках уникальную программу, которая в перспективе нужна всем трейдерам, фирма полностью отошла от торговли и сфокусировалась на разработке программного обеспечения.
Сегодня Itiviti – это международная софтверная компания с 18 офисами по всему миру. Наш софт используется банками, хедж фондами, трейдинговыми компаниями, брокерами и многими другими участниками торговли на биржах.
Недавно мы стали частью компании Broadridge Financial Solutions.
Одно из наших основных направлений – разработка супер быстрого софта для высокочастотной торговли на электронных биржах – торговой системы Tbricks. В нашем деле главный показатель качества – это скорость! Стоит остановиться или замедлиться, тебя догонят. Чтобы оставаться самыми быстрыми, мы постоянно занимаемся оптимизациями. Про один из кейсов оптимизации продукта мы сегодня и расскажем в этой статье.
Разработкой системы Tbricks я уже занимаюсь около 12 лет и как ее архитектор я слежу за тем, чтобы платформа двигалась в правильном технологическом направлении, активно развивалась и, конечно, не проигрывала конкурентам по производительности.
В этой статье хочу рассказать про то, как мы работаем с многопоточностью, разбираем связанные с ней проблемы производительности, а также поделиться интересными подходами, которые мы используем для тюнинга нашего софта.
NB! Перед тем, как мы начнем, хочу выразить благодарность моим коллегам Шарунасу и Сергею, без вас всего бы этого не было.
Итак, поехали!
Не так давно я стал замечать, что наша система иногда не очень хорошо справляется с активной торговлей ETF-ами на американских рынках, в особенности когда рынки очень активны. После анализа стало понятно, что одним из проблемных мест является получение данных с агрегаторов, которые в реальном времени предоставляют котировки одновременно с нескольких десятков бирж. В этой статье я поделюсь опытом, как мы с командой решали эту проблему.
Для начала поймем, как вообще котировки попадают к конечным пользователям – трейдерам или торговым алгоритмам, и зачем они им нужны. Обычно за получение котировок с биржи отвечает специальная компонента, которая называется «гейтвей» (gateway). В ее задачу входит подключаться по сети к бирже (как правило это Multicast, хотя встречаются и UDP, и TCP, но реже), декодировать входящие сообщения в более понятный для торговой системы формат (нормализовать) и затем уже доставлять необходимые значения конечным пользователям. На основе этих котировок трейдер или торговый алгоритм принимает решение, послать заказ на рынок или нет.

Эффективность торговых алгоритмов напрямую зависит от того, насколько быстро они получают актуальные котировки с биржи. Поэтому очень важной является задача оптимизации гейтвея, чтобы он не только мог обрабатывать огромное количество котировок (бывает с рынка приходит несколько сотен миллионов сообщений в день), но при этом обеспечивал их максимально быструю доставку до торговых алгоритмов. Также очень важно отсутствие больших outliers в распределении времени доставки котировок до алгоритмов на 99%-100% перцентилях.
Еще интереснее дело обстоит с агрегаторами: чем больше бирж объединяет агрегатор, тем больше котировок будет приходить в гейтвей. Как следствие гейтвей должен быть еще быстрее, чтобы обеспечить хорошую скорость передачи и обработки данных.
Объемы электронной торговли растут каждый год, а за последние 10 лет еще и появилось много новых бирж. Для примера приведу статистику по американскому агрегатору OPRA SIP за последние 5 лет (ссылка):
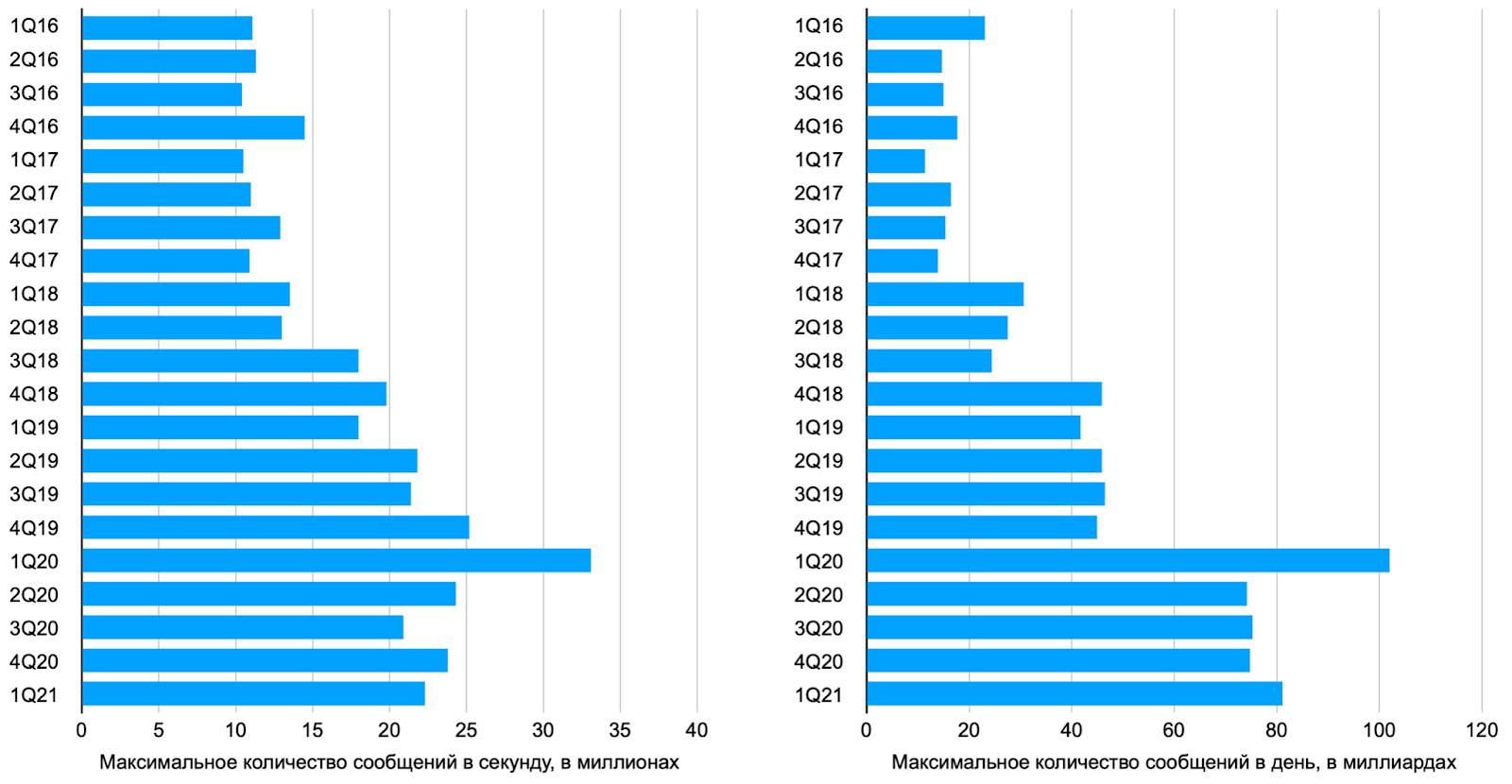
Как видно, в марте 2020-го года, когда из-за повсеместно введенных локдаунов на рынках начался обвал, кол-во котировок поступающих к OPRA SIP с бирж в пике достигало 33.1 млн сообщений в секунду, что более чем в 2 раза превышает пиковые показатели 2016 года. А максимальное количество котировок в день росло примерно +45% от года к году и выросло примерно в 4,4 раз с 2016 по 2020 год.
В итоге, мы поняли, что наши гейтвеи к площадкам-агрегаторам перестали справляться с постоянно возрастающей нагрузкой и скоростные характеристики гейтвеев начали падать. В какой-то момент стало понятно, что простых оптимизаций уже не хватает, поэтому назрела необходимость каких-то архитектурных изменений в гейтвеях.
Рассмотрим подробнее, как гейтвеи работали раньше. Упрощенно гейтвей состоит из нескольких функциональных блоков, следующих друг за другом:

Receive
Получение сообщения из сети и декодирование базовых параметров: тип сообщения (котировка или цена последней сделки и др.), финансовый инструмент (что это за акция или фьючерс и т.д).
Update
Обновление внутренней структуры в памяти с информацией по конкретному финансовому инструменту, как например текущая лучшая цена (bbo) или информация по биржевому стакану (order book).
Эта часть не зависит от внешних параметров и хорошо оптимизирована. Все необходимая логика выполняется в пределах 1 мкс согласно нашим измерениям (а в большинстве случаем в пределах 20-100 нс).
Flush
После того как данные обновлены, их надо нормализовать и отправить всем заинтересованным конечным пользователям (подписчикам). Время выполнения этого шага прямо пропорционально количеству подписчиков и типу подписки (какую непосредственно информацию подписчик хочет получать). Если подписчиков нет, то шаг Flush пропускается.
Post-processing
На этом шаге может проводится дополнительный анализ сообщения, его запись (audit) и другие функции в зависимости от конфигурации гейтвея.
Таким образом гейтвей внутри организован как показано на рисунке
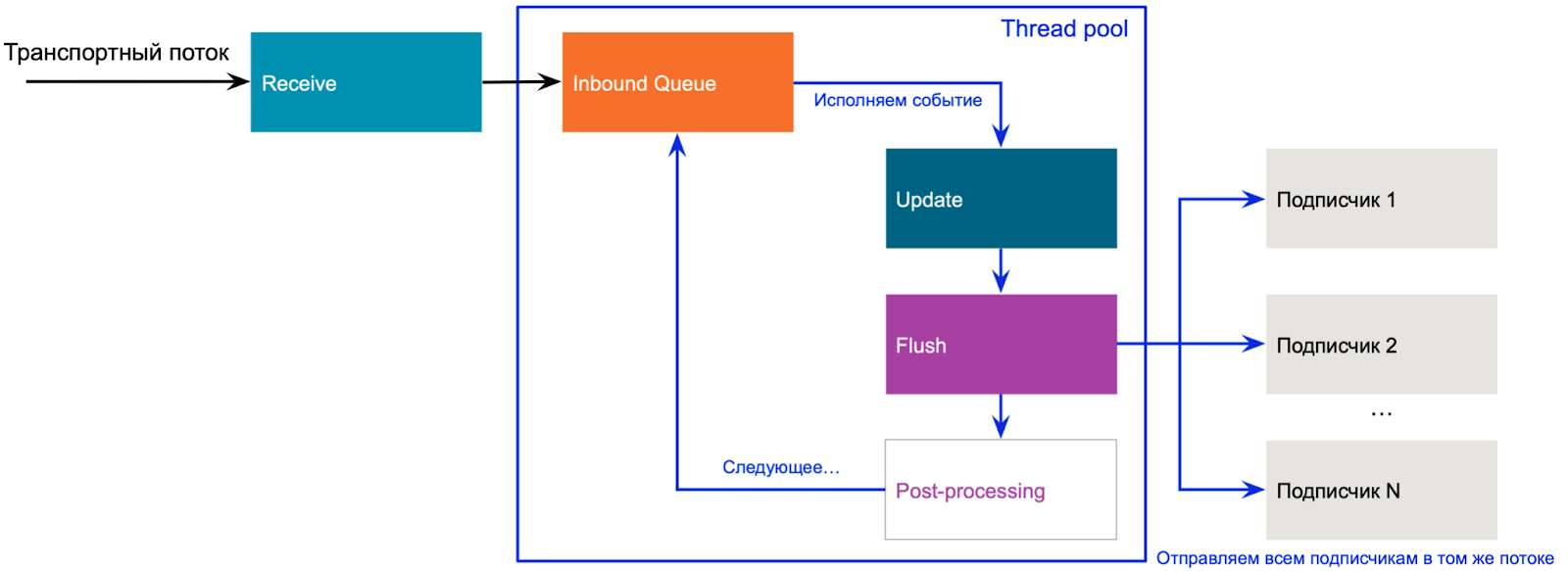
Когда приходит новая котировка, транспортный поток выполняет блок Receive, создает событие (market data event) и помещает его в очередь событий для этого инструмента (чтобы сериализовать все обновления одного и того же инструмента). События обрабатываются в другом пуле потоков, исполняя последовательно шаги Update, Flush и Post-processing. Диспетчеризация была поручена Grand Central Dispatch (или просто GCD).
До недавнего времени такая организация работы позволяла достаточно эффективно обрабатывать входящий поток котировок и обеспечивать хорошую скорость их доставки подписчикам. Однако по причинам, описанным выше, на сегодняшний день эта схема работает уже не так быстро, как хотелось бы!
Итак, как мы с этим справились?
Параллельно, а не последовательно!
Изначально проблемы начали проявляться в моменты гиперактивности на биржах (например, когда Трамп что-нибудь такое твитнет про Китай или во время Brexit). Основным индикатором проблем стали растущие очереди событий для инструментов. Пул потоков не успевал обрабатывать входящие сообщения (котировки) из-за того, что блоки Flush и Post-processing могли выполняться достаточно долго. Как результат – растущая память, и, что намного хуже, торговые стратегии могли получить неактуальные цены и послать заказ по неправильной цене, а это верный способ потерять деньги.
Логичным шагом здесь стало решение развязать шаги Flush и Post-processing, чтобы выполнять их параллельно, а не последовательно. После некоторого рефакторинга кода это удалось сделать, однако встал интересный вопрос об изменении thread model.
В новой схеме результат выполнения блока Update должен приводить к независимому выполнению блоков Flush и Post-processing в разных пулах потоков, причем скорость, с которой сообщения будут разбираться, разная и предсказать ее сложно.
Thread Model
Заменив очереди по инструментам на одну Inbound Queue, мы получили следующий порядок работы (см. рисунок):
Транспортный поток вычитывает сообщение из сети и опционально перекладывает его в Inbound Queue
Блок Update выполняется либо в транспортном потоке (как было сказано выше, эта операция хорошо оптимизирована и очень быстрая), либо потоком из Update Thread Pool. После выполнения блока Update результат отправляется в Outbound Queue.
Блоки Flush и Post-processing выполняются независимо друг от друга потоками из соответствующих пулов.

Как видно на рисунке, теперь выполнение блока Update не зависит от количества подписчиков или сложности post-processing. Более того, теперь это время можно считать более-менее гарантированным. Однако сделали мы это ценой возможного роста Outbound Queue (так как теперь в этой очереди происходит самая долгая и непредсказуемая операция Flush на пути до подписчиков) и увеличением количества событий в очередях. Так для обработки одного события с биржи требуется 2 события для Outbound Queue (Flush и Post-processing), а так же опционально +1 дополнительное событие для Inbound Queue — итого до 3-х событий.
Disruptor
Как показала наша практика, GCD работает достаточно неплохо, однако при большом количестве очередей и событий нужно быть готовым получить накладные расходы на добавление в очередь до 4 микросекунд + возможные outliers (см. рисунок)

Здесь мы решили обратить внимание на Disruptor. Правда была проблема, пишем мы на С++, а никакой официальной версии Disruptor на С++ нет. На тот момент существовало несколько неофициальных реализаций на С++, но ни одна нам не подошла (по разным причинам). Поэтому мы сделали свою реализацию. Вообще, как мы к этому пришли, с какими столкнулись сложностями и как их решали – достойно отдельной публикации. Пишите в комментариях, если вам интересен разбор этого кейса и мы сделаем отдельный пост!

Переведя Inbound Queue и Outbound Queue очереди на Disruptor мы получили первые существенные улучшения во времени обработки входящих сообщений. Так время сократилось с 7 мкс до 3 мкс в 75% случаев (см графики), но при этом существенно выросли outliers (на 90% — 99% перцентилях).
Анализ ситуации выявил, что раньше, имея узкое место во входных очередях, мы не особо замечали проблем со скоростью посылки сообщений подписчикам, даже если подписчиков много, так как вызывали операцию Flush реже! Теперь же именно время отправки сообщений подписчикам стало проблемой, причем в худшем случае (а это как раз гиперактивность на рынке) наши оптимизации ухудшили время доставки сообщения подписчикам.
Но на самом деле, ничего нового, оптимизация в одном месте часто приводит к перемещению проблем в другое место, причем не факт, что в целом станет лучше. Так и получилось в нашем случае. Окей, работаем дальше!
Объединение сообщений
Чтобы решить проблему, мы применили еще одну практику, которую уже неоднократно применяли в других частях нашей системы – объединение сообщений (от англ. coalescing). Идея состоит в том, чтобы не посылать каждое входящее сообщение с биржи всем подписчикам, а объединять несколько котировок на один и тот же инструмент и делать Flush с какой-то периодичностью.
# | Time | Received Price | Received Volume | Sent Price | Sent Volume |
1 | +0µs | 10.00 | 100 | 10.0 | 100 |
2 | +5µs | 10.05 | 101 | ||
3 | +10µs | 10.05 | 102 | ||
4 | +15µs | 10.00 | 102 | 10.00 | 102 |
Конечно, минус тут в том, что торговый алгоритм не получит сообщение, что цена была 10.05, но это несравненно лучше, чем послать котировку с ценой 10.05, когда она уже заведомо 10.00.
Вторая хитрость в том, что если выполняется какое-то заранее оговоренное условие, например, если цена меняется слишком сильно (скажем +/- 1%), то стоит сразу же сделать Flush и не ждать, когда сработает таймер.
Для реализации этого подхода в описанной выше схеме мы разделили Outbound Queue на Throttle Queue и Priority Queue (см рисунок). После выполнения блока Update если событие должно быть отправлено без задержек, то оно напрямую помещается в Priority Queue. В остальных случаях событие помещается в Throttle Queue. Когда срабатывает таймер, объединенные события из Throttle Queue помещаются с Priority Queue и уже посылаются потоками из Flushing Thread Pool.

В итоге, объединение сообщений позволило существенно сократить количество вызовов блока Flush. Чтобы это доказать, мы провели тест на основе записи реальных сообщений с площадки агрегатора.
Он показал, что 42% сообщений в итоге проходили через Throttle Queue. А убрав проблему outliers, мы увидели улучшение времени доставки сообщений до подписчиков более чем в два раза с 7 мкс до 3 мкс практически для всех событий (до 99.9 перцентили). Мы уже установили новое решение нескольким клиентам и видим, что сделанный подход намного лучше справляется с активностью на рынках.
