
GTA Online печально известна своей медленной скоростью загрузки. Запустив недавно игру, чтобы выполнить новые миссии-налёты, я был шокирован тем, что она загружается так же медленно, как и в момент выпуска семь лет назад.
Время настало. Пора разобраться в причинах этого.
Разведка
Для начала я захотел проверить, не решил ли уже кто-нибудь эту проблему. Большинство найденных результатов состояло из анекдотичных данных о том, насколько сложна игра, что ей приходится грузиться так долго, историй об отстойности сетевой архитектуры p2p (и в этом есть правда), сложных способов загрузки в сюжетный режим, а после него в одиночную сессию и пары модов, позволявших пропустить начальное видео с логотипом компании R*. Некоторые источники сообщали, при совместном использовании всех этих способов можно сэкономить аж целых 10-30 секунд!
Тем временем на моём PC…
Бенчмарк
Время загрузки сюжетного режима: около 1 мин 10 с
Время загрузки онлайн-режима: около 6 мин 0 с
Меню запуска отключено, время от появления логотипа R* до начала самого игрового процесса (время логина в social club не считается).
Старый, но приличный ЦП: AMD FX-8350
Дешёвый SSD: KINGSTON SA400S37120G
Без оперативки не обойтись: 2 модуля Kingston 8192 МБ (DDR3-1337) 99U5471
Относительно неплохой GPU: NVIDIA GeForce GTX 1070
Понимаю, что моя машина устарела, но какого чёрта онлайн-режим загружается в шесть раз медленнее? Я не смог обнаружить никаких отличий при использовании техники загрузки «сначала сюжет, потом онлайн», как это удалось сделать другим до меня. Но даже бы если это сработало, то результаты находились бы в рамках погрешности.
Я не одинок
Если поверить этому опросу, то проблема настолько распространена, что слегка подбешивает более 80% базы игроков. Ребята из R*, вообще-то уже семь лет прошло!

У 18,8% игроков мощнейшие компьютеры или консоли, у 81,2% всё довольно грустно, у 35,1% — совсем печально.
Поискав 20% тех счастливчиков, загрузка у которых занимает меньше трёх минут, я нашёл некоторое количество бенчмарков с мощными игровыми PC и временем загрузки онлайн-режима примерно две минуты. Чтобы получить время загрузки в две минуты я бы
Как получилось, что людей, делавших эти бенчмарки, загрузка сюжетного режима всё равно занимает примерно минуту? (Кстати, в бенчмарке с M.2 не учтено время показа логотипов в начале.) Кроме того, загрузка из сюжетного в онлайн-режим занимает у них всего минуту, а у меня — больше пяти. Я знаю, что у них техника намного лучше моей, но точно не в пять раз.
Очень точные измерения
Вооружённый такими мощными инструментами, как Диспетчер задач, я начал расследование, чтобы выяснить, какие ресурсы могут быть «узким местом».
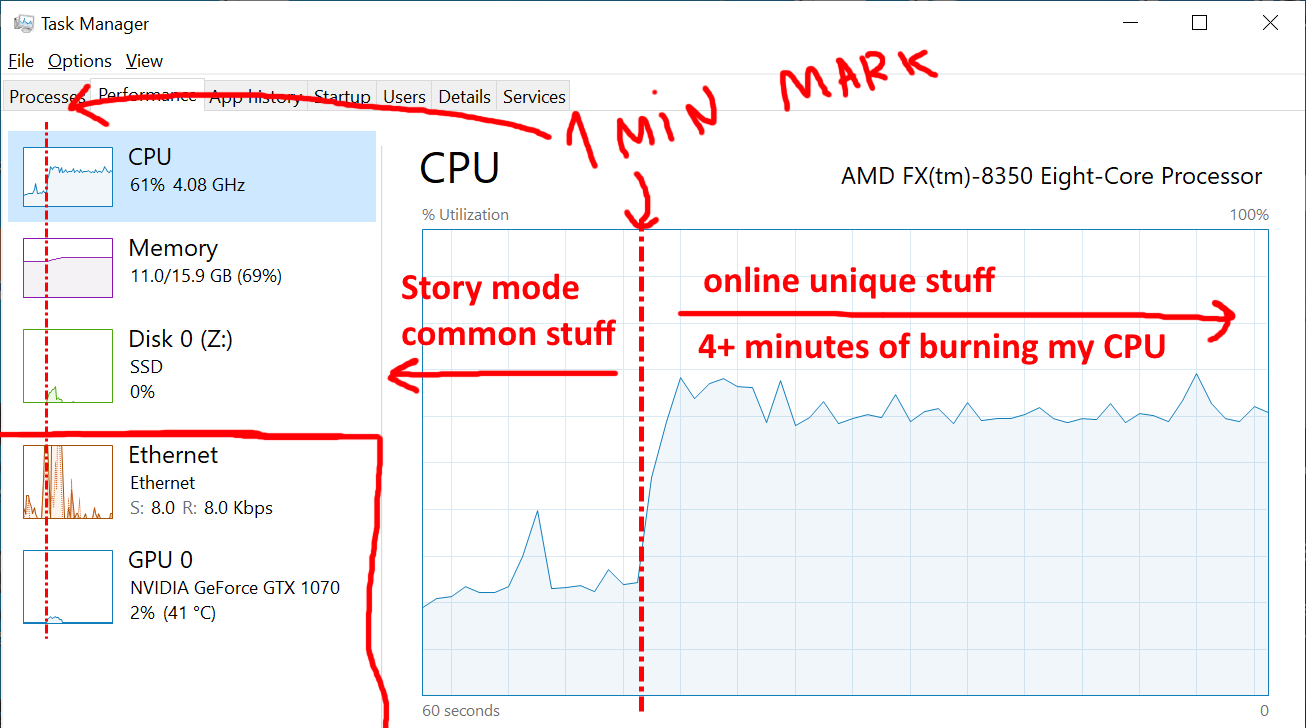
В течение одной минуты загружаются стандартные ресурсы сюжетного режима, после чего игра в течение четырёх с лишним минут грузит процессор.
После минуты загрузки общих ресурсов, используемых и в сюжетном, и в онлайн-режимах (показатель, почти равный бенчмаркам мощных PC) GTA решает максимально нагружать одно ядро моей машины в течение четырёх минут и больше ничего не делать.
Обращение к диску? Его нет! Использование сети? Есть немного, но спустя всего несколько секунд трафик падает почти до нуля (кроме загрузки вращающихся баннеров с информацией). Использование GPU? По нулям. Использование памяти? Совершенно плоский график…
Что происходит, игра майнит крипту, или ещё чего? Начинает попахивать кодом. Очень плохим кодом.
Ограничение одним потоком
Хотя мой старый ЦП AMD имеет восемь ядер и всё ещё может себя показать, он был создан в старые времена. Тогда однопоточная производительность процессоров AMD намного отставала от показателей процессоров Intel. Возможно, это и не объясняет всю разницу во времени загрузки, но должно объяснить самое главное.
Странно то, что игра использует только ЦП. Я ожидал огромного объёма загружаемых с диска ресурсов или кучу сетевых запросов для создания сессии в сети p2p. Но это? Скорее всего, это баг.
Профилирование
Профилировщики — отличный способ поиска «узких мест» в работе ЦП. Есть только одна проблема — большинство из них для получения идеальной картины происходящего в процессе использует исходный код. А у меня его нет. Но мне не нужны и показания с точностью до микросекунд — «узкое место» длится целых четыре минуты.
На сцене появляется сэмплирование стека: это единственный вариант изучения приложений с закрытыми исходниками. Выполняем дамп стека запущенного процесса и местоположения указателя текущей команды, чтобы строить дерево вызовов с заданными интервалами. Затем складываем их, чтобы получить статистику о происходящем. Есть только один известный мне профилировщик (здесь я могу ошибаться), способный на такое в Windows. И он не обновлялся больше десяти лет. Это Luke Stackwalker! Пусть кто-нибудь подарит этому проекту свою любовь.

Виновники №1 и №2.
Обычно Luke группирует одинаковые функции, но поскольку у меня нет отладочных символов, мне нужно глазами просматривать ближайшие адреса, чтобы понять, что это одно и то же место. И что же мы видим? Не одно, а целых два «узких места»!
Вниз по кроличьей норе
Позаимствовав у друга совершенно законную копию популярного дизассемблера (нет, я не могу себе его позволить… придётся как-нибудь изучить ghidra), я приступил к разборке GTA.
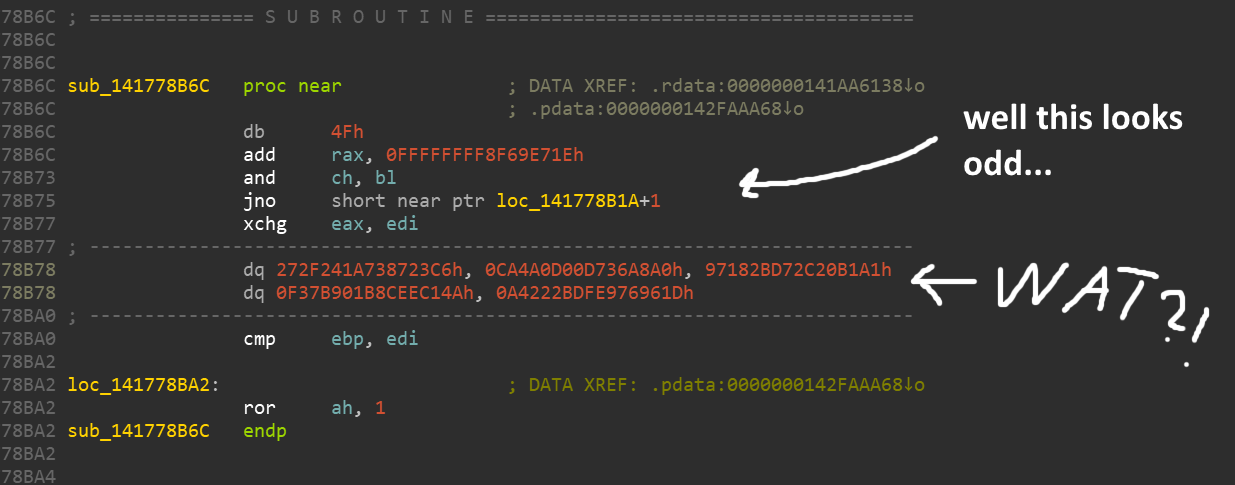
Всё это кажется совсем неправильным. Многие высокобюджетные игры имеют встроенную защиту от реверс-инжиниринга, чтобы защититься от пиратов, читеров и моддеров (не сказать, чтобы это когда-то их останавливало).
Похоже, здесь используется некая обфускация/шифрование, из-за которого большинство команд заменено абракадаброй. Но не волнуйтесь, нам просто нужно сдампить память игры в момент выполнения части, которую мы хотим изучить. Перед своим выполнением команды тем или иным способом должны деобфусцироваться. У меня был под рукой Process Dump, но есть множество других инструментов, способных выполнять подобные функции.
Проблема №1: это… strlen?!
При дизассемблировании теперь уже менее обфусцированного дампа обнаруживается, что один из адресов имеет метку, взятую ниоткуда! Это
strlen? Следующий вниз по стеку вызовов помечен как vscan_fn, после чего метки заканчиваются, однако я практически уверен, что это sscanf.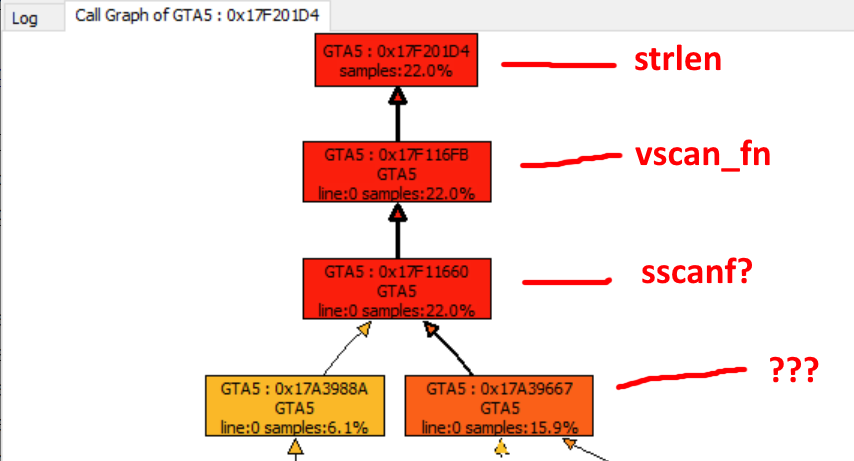
Они что-то парсят. Но что? Разбор дизассемблированного кода занял бы бесконечность, поэтому я решил сдампить некоторые сэмплы из запущенного процесса при помощи x64dbg. Проведя пошаговую отладку, я выяснил, что это… JSON! Они парсят JSON. Целых 10 мегабайт данных JSON с почти 63 тысячами элементов.
...,
{
"key": "WP_WCT_TINT_21_t2_v9_n2",
"price": 45000,
"statName": "CHAR_KIT_FM_PURCHASE20",
"storageType": "BITFIELD",
"bitShift": 7,
"bitSize": 1,
"category": ["CATEGORY_WEAPON_MOD"]
},
...Что это? Согласно некоторым источникам, это похоже на данные «каталога сетевого магазина». Предположу, что они содержат список всех возможных предметов и апгрейдов, которые можно купить в GTA Online.
Уточнение: я считаю, что это предметы, покупаемые за внутриигровые деньги, а не связанные напрямую с микротранзакциями.
Но 10 мегабайт — это ведь мелочь! А использование
sscanf пусть и не оптимально, но не может же оно быть настолько плохим? Ну-у-у…
10 мегабайт строк C в памяти. 1. Перемещаем указатель на несколько байт к следующему значению. 2. Вызываем
sscanf(p, "%d", ...). 3. Считываем каждый символ в 10 мегабайтах при считывании каждого мелкого значения (!?). 4. Возвращаем отсканированное значение.Да, это займёт много времени… Честно говоря, я понятия не имел, что большинство реализаций
sscanf вызывает strlen, поэтому не могу винить написавшего это разработчика. Я бы предположил, что эти данные просто сканируются байт за байтом и обработка может остановиться на NULL.Проблема №2: давайте используем хэш-… массив?
Оказалось, что второй виновник вызывается непосредственно рядом с первым. Они оба даже вызываются в одном операторе
if, как можно понять в этой уродливой декомпиляции:
Обе проблемы находятся внутри одного большого цикла парсинга всех предметов. Проблема №1 — парсинг, проблема №2 — сохранение.
Все метки указаны мной, я понятия не имею, как по-настоящему называются функции и параметры.
В чём же заключается вторая проблема? Сразу после парсинга предмета он сохраняется в массив (или во встроенный список C++? не совсем понятно). Каждый предмет выглядит примерно так:
struct {
uint64_t *hash;
item_t *item;
} entry;Но что происходит перед сохранением? Код проверяет весь массив, один элемент за другим, сравнивая хэш предмета, чтобы понять, находится ли он в списке. Если мои вычисления верны, то при примерно 63 тысячах элементов это даёт
(n^2+n)/2 = (63000^2+63000)/2 = 1984531500 проверок. Большинство из них бесполезно. У нас есть уникальные хэши, так почему бы не использовать hash map?
Профилировщик показывает, что процессор нагружают первые две строки. Оператор
if выполняется только в самом конце. Предпоследняя строка вставляет предмет.В процессе обратной разработки я назвал эту структуру
hashmap, однако очевидно, что это not_a_hashmap. И дальше всё становится только лучше. Этот хэш/массив/список перед загрузкой JSON пуст. И все предметы в JSON уникальны! Коду даже не нужно проверять, есть ли предмет в списке! Есть даже функция для непосредственной вставки предметов, достаточно просто использовать её! Серьёзно, чё за фигня!?Proof of Concept
Всё это конечно здорово, но никто не воспримет меня всерьёз, пока я это не протестирую, чтобы можно было написать к посту кликбейтный заголовок.
Каким будет план? Написать
.dll, инъецировать её GTA, перехватить несколько функций, ???, ПРОФИТ!Проблема с JSON запутанна, и замена парсера окажется чрезвычайно трудоёмкой задачей. Гораздо реалистичнее будет попытаться заменить
sscanf на функцию, не зависящую от strlen. Но есть ещё более простой способ.- перехватить strlen
- дождаться длинной строки
- «кэшировать» её начало и длину
- если она снова вызывается в пределах строки, возвращать кэшированное значение
Что-то типа такого:
size_t strlen_cacher(char* str)
{
static char* start;
static char* end;
size_t len;
const size_t cap = 20000;
// если у нас есть "кэшированная" строка и текущий указатель находится внутри неё
if (start && str >= start && str <= end) {
// вычисляем новую strlen
len = end - str;
// если мы близки к концу, выгружаемся
// не нужно вмешиваться во что-то посторонее
if (len < cap / 2)
MH_DisableHook((LPVOID)strlen_addr);
// супербыстрый возврат!
return len;
}
// подсчитываем истинную длину
// нам нужно хотя бы одно измерение для большого JSON
// или обычная strlen для других строк
len = builtin_strlen(str);
// если это была очень длинная строка
// сохраняем адреса её начала и конца
if (len > cap) {
start = str;
end = str + len;
}
// медленный скучный возврат
return len;
}Что касается проблемы хэш-массива, то с ней всё проще — можно просто полностью пропускать дублирующиеся проверки и вставлять предметы напрямую, потому что мы знаем, что значения уникальны.
char __fastcall netcat_insert_dedupe_hooked(uint64_t catalog, uint64_t* key, uint64_t* item)
{
// я не стал заморачиваться реверс-инжинирингом этой структуры
uint64_t not_a_hashmap = catalog + 88;
// понятия не имею, что делает эта строка, но повторил то, что было в оригинальном коде
if (!(*(uint8_t(__fastcall**)(uint64_t*))(*item + 48))(item))
return 0;
// непосредственная вставка
netcat_insert_direct(not_a_hashmap, key, &item);
// удаляем перехватчики после добирания до хэша последнего предмета
// и выгружаем .dll, на этом всё :)
if (*key == 0x7FFFD6BE) {
MH_DisableHook((LPVOID)netcat_insert_dedupe_addr);
unload();
}
return 1;
}Полные исходники proof of concept находятся здесь.
Результаты
Ну и как, сработало?
Исходное время загрузки онлайн-режима: примерно 6 мин
Время только с пропатченными дублируемыми проверками: 4 мин 30 с
Время только с патчем парсера JSON: 2 мин 50 с
Время с патчами обеих проблем: 1 мин 50 с
(6*60 — (1*60+50)) / (6*60) = время загрузки уменьшилось на 69.4% (отлично!)
О да, ещё как сработало!
Скорее всего, это не уменьшит время загрузки у всех игроков — на других системах могут быть другие «узкие места», но это настолько очевидная проблема, что я не понимаю, как R* не замечала её все эти годы.
tl;dr
- При запуске GTA Online есть узкое место ЦП из-за однопотокового выполнения
- Оказывается, в это время GTA сражается с парсингом 10-мегабайтного файла JSON
- Сам парсер JSON плохо написан/наивно реализован и
- После парсинга выполняется медленная процедура проверки отсутствия дубликатов предметов
R*, пожалуйста, решите проблему
Просьба, если эта статья каким-то образом доберётся до Rockstar: на решение этих проблем не уйдёт больше дня работы одного разработчика. Пожалуйста, сделайте с этим что-нибудь.
Можно перейти на hashmap для устранения дубликатов или полностью пропускать эту проверку, что будет реализовать быстрее. В парсере JSON замените библиотеку на более производительную. Не думаю, что здесь есть более простое решение.
Спасибо.










